(换肤)
语言:

文章编号:16021时间:2024-03-02人气:
【新智元导读】 早已成为大模型时代的基础。国外一位开发者颁布了一篇通常指南,仅用60行代码构建GPT。
60行代码,从头开局构建GPT?
最近,一位开发者做了一个通常指南,用Numpy代码从头开局成功GPT。
你还可以将OpenAI颁布的GPT-2模型权重加载到构建的GPT中,并生成一些文本。
话不多说,间接开局构建GPT。
什么是GPT?
GPT代表生成式预训练Transformer,是一种基于Transformer的神经网络结构。
-生成式(Generative):GPT生成文本。
-预训练(Pre-trained):GPT是依据书本、互联网等中的少量文本启动训练的。
-Transformer:GPT是一种仅用于解码器的Transformer神经网络。
大模型,如OpenAI的GPT-3、谷歌的LaMDA,以及Cohere的CommandXLarge,面前都是GPT。它们的特意之处在于,1)十分大(领有数十亿个参数),2)受过少量数据(数百GB的文本)的训练。
直白讲,GPT会在提醒符下生成文本。
即使经常使用十分繁难的API(输入=文本,输入=文本),一个训练有素的GPT也可以做一些十分棒的事件,比如写邮件,总结一本书,为Instagram发帖提供想法,给5岁的孩子解释黑洞,用SQL编写代码,甚至写遗言。
以上就是GPT及其性能的概述。让咱们深化了解更多细节。
输入/输入
GPT定义输入和输入的格局大抵如下所示:
输入是由映射到文本中的token的一系列整数示意的一些文本:
Token是文本的子片段,经常使用分词器生成。咱们可以经常使用词汇表将token映射到整数:
简而言之:
-有一个字符串。
-经常使用分词器将其合成成称为token的小块。
-经常使用词汇表将这些token映射为整数。
在通常中,咱们会经常使用更先进的分词方法,而不是繁难地用空白来宰割,比如字节对编码(BPE)或WordPiece,但原理是一样的:
vocab将字符串token映射为整数索引
encode方法,可以转换str->list[int]
decode方法,可以转换list[int]->str([2])
输入
输入是一个二维数组,其中output[i][j]是模型预测的概率,即vocab[j]处的token是下一个tokeninputs[i+1]。例如:
#["all","not","heroes","the","wear",".","capes"]#output[1]=[0.00.00.80.10.00.00.1]#giventhesequence["not","all"],themodelpredictstheword"heroes"withthehighestprobability
#["all","not","heroes","the","wear",".","capes"]#output[-1]=[0.00.00.00.10.00.050.85]#giventhewholesequence["not","all","heroes","wear"],themodelpredictstheword"capes"withthehighestprobability
要取得整个序列的下一个token预测,咱们只需失掉output[-1]中概率的token:
将概率的token作为咱们的预测,称为贪心解码(GreedyDecoding)或贪心采样(greedysampling)。
预测序列中的下一个逻辑词的义务称为言语建模。因此,咱们可以将GPT称为言语模型。
生成一个单词很酷,但整个句子、段落等又如何呢?
生成文本
自回归
咱们可以经过迭代从模型中取得下一个token预测来生成完整的句子。在每次迭代中,咱们将预测的token追加回输入:
input_ids=[1,0]#"not""all"output_ids=generate(input_ids,3)#output_ids=[2,4,6]output_tokens=[vocab[i]foriinoutput_ids]#"heroes""wear""capes"
这个预测未来值(回归)并将其参与回输入(自)的环节,就是为什么你或许会看到GPT被形容为自回归的要素。
采样
咱们可以从概率散布中采样,而不是贪心采样,从而为生成的引入一些随机性:
这样,咱们就能在输入相反内容的状况下生成不同的句子。
假设与top-k、top-p和温度等在采样前修正散布的技术相联合,咱们的输入品质就会大大提高。
这些技术还引入了一些超参数,咱们可以应用它们来取得不同的生成行为(例如,提高温度会让咱们的模型承当更多危险,从而更具「发明性」)。
训练
咱们可以像训练其余神经网络一样,经常使用梯度降低法训练GPT,并计算损失函数。关于GPT,咱们驳回言语建模义务的交叉熵损失:
这是一个经过少量简化的训练设置,但可以说明疑问。
请留意,咱们在gpt函数签名中参与了params(为了繁难起见,咱们在前面的章节中没有参与)。在训练循环的每一次性迭代时期:
-关于给定的输入文本实例,计算了言语建模损失
-损失选择了咱们经过反向流传计算的梯度
-咱们经常使用梯度来更新咱们的模型参数,以使损失最小化(梯度降低)
请留意,咱们不经常使用显式标志的数据。相反,咱们能够仅从原始文本自身生成输入/标签对。这被称为自监视学习。
自监视使咱们能够大规模裁减训练数据,只需取得尽或许多的原始文本并将其投放到模型中。例如,GPT-3接受了来自互联网和书籍的3000亿个文本token的训练:
当然,你须要一个足够大的模型才干从一切这些数据中学习,这就是为什么GPT-3有1750亿个参数,训练的计算老本或许在100万至1000万美元之间。
这个自监视的训练步骤被称为预训练,由于咱们可以重复经常使用「预训练」的模型权重来进一步训练模型的下游义务。预训练的模型有时也称为「基础模型」。
在下游义务上训练模型称为微调,由于模型权重曾经经过了了解言语的预训练,只是针对手头的特定义务启动了微调。
「普通义务的前期训练+特定义务的微调」战略被称为迁徙学习。
提醒
准则上,最后的GPT论文只是关于预训练Transformer模型用于迁徙学习的好处。
论文标明,当对标志数据集启动微调时,预训练的117MGPT在各种自然言语处置义务中取得了进的性能。
直到GPT-2和GPT-3论文宣布后,咱们才看法到,基于足够的数据和参数预训练的GPT模型,自身能够执行任何义务,不须要微调。
只需提醒模型,执行自回归言语建模,而后模型就会神奇地给出适当的照应。这就是所谓的「高低文学习」(in-contextlearning),由于模型只是应用提醒的高低文来成功义务。
语境中学习可以是0次、一次性或屡次。
在给定提醒的状况下生成文本也称为条件生成,由于咱们的模型是依据某些输入生成一些输入的。
GPT并不局限于NLP义务。
你可以依据你想要的任何条件来微调这个模型。比如,你可以将GPT转换为聊天机器人(如ChatGPT),方法是以对话历史为条件。
说到这里,让咱们最起初看看实践的成功。
设置
克隆本教程的存储库:
而后装置依赖项:
留意:这段代码是用Python3.9.10测试的。
每个文件的繁难分类:
-encoder.py蕴含OpenAI的BPE分词器的代码,这些代码间接取自gpt-2repo。
-utils.py蕴含下载和加载GPT-2模型权重、分词器和超参数的代码。-gpt2.py蕴含实践的GPT模型和生成代码,咱们可以将其作为python脚本运转。-gpt2_pico.py与gpt2.py相反,但代码行数更少。
咱们将从头开局从新成功gpt2.py,所以让咱们删除它并将其从新创立为一个空文件:
首先,将以下代码粘贴到gpt2.py中:
将4个局部区分合成为:
-gpt2函数是咱们将要成功的实践GPT代码。你会留意到,除了inputs之外,函数签名还包括一些额外的内容:
wte、wpe、blocks和ln_f是咱们模型的参数。
n_head是前向传递环节中须要的超参数。
-generate函数是咱们前面看到的自回归解码算法。为了繁难起见,咱们经常使用贪心抽样。tqdm是一个进度条,协助咱们可视化解码环节,由于它一次性生成一个token。
-main函数处置:
加载分词器(encoder)、模型权重(params)和超参数(hparams)
经常使用分词器将输入提醒编码为tokenID
调用生成函数
将输入ID解码为字符串
fire.Fire(main)只是将咱们的文件转换为CLI运行程序,因此咱们最终可以经常使用pythongpt2.py"someprompthere"运转代码
让咱们更详细地了解一下笔记本中的encoder、hparams和params,或许在交互式的Python会话中,运转:
这将把必要的模型和分词器文件下载到models/124M,并将encoder、hparams和params加载到咱们的代码中。
编码器
encoder是GPT-2经常使用的BPE分词器:
经常使用分词器的词汇表(存储在encoder.decoder中),咱们可以看到实践的token是什么样子的:
请留意,咱们的token有时是单词(例如Not),有时是单词但前面有空格(例如Ġall,Ġ示意空格),有时是单词的一局部(例如Capes分为Ġcap和es),有时是标点符号(例如.)。
BPE的一个优势是它可以对恣意字符串启动编码。假设它遇到词汇表中没有的内容,它只会将其合成为它能够了解的子字符串:
咱们还可以审核词汇表的大小:
词汇表以及确定如何拆分字符串的字节对兼并是经过训练分词器取得的。
当咱们加载分词器时,咱们从一些文件加载曾经训练好的单词和字节对兼并,当咱们运转load_encoder_hparams_and_params时,这些文件与模型文件一同下载。
超参数
hparams是一个蕴含咱们模型的超参数的词典:
咱们将在代码的注释中经常使用这些符号来显示事物的基本状态。咱们还将经常使用n_seq示意输入序列的长度(即n_seq=len(inputs))。
参数
params是一个嵌套的json字典,它保留咱们模型的训练权重。Json的叶节点是NumPy数组。咱们会失掉:
这些是从原始OpenAITensorFlow审核点加载的:
上方的代码将上述TensorFlow变量转换为咱们的params词典。
作为参考,以下是params的状态,但用它们所代表的hparams交流了数字:
基本层
在咱们进入实践的GPT体系结构自身之前,最后一件事是,让咱们成功一些非特定于GPT的更基本的神经网络层。
GPT-2选用的非线性(激活函数)是GELU(高斯误差线性单元),它是REU的替代方案:
它由以下函数近似示意:
与RELU相似,Gelu在输入上按元素操作:
Goodolesoftmax:
咱们经常使用max(x)技巧来保障数值稳固性。
SoftMax用于将一组实数(介于−∞和∞之间)转换为概率(介于0和1之间,一切数字的总和为1)。咱们在输入的最后一个轴上运行softmax。
层归一化
层归一化将值规范化,使其平均值为0,方差为1:
层归一化确保每一层的输入一直在分歧的范围内,这会放慢和稳固训练环节。
与批处置归一化一样,归一化输入随后被缩放,并经常使用两个可学习向量gamma和beta启动偏移。分母中的小epsilon项用于防止除以零的误差。
由于种种要素,Transformer驳回分层定额替代批量定额。
咱们在输入的最后一个轴上运行层归一化。
你的规范矩阵乘法+偏向:
线性层通常称为映射(由于它们从一个向量空间映射到另一个向量空间)。
GPT架构
GPT架构遵照Transformer的架构:
从上档次上讲,GPT体系结构有三个局部:
文本+位置嵌入
一种transformer解码器堆栈
向单词步骤的映射
在代码中,它如下所示:
把一切放在一同
把一切这些放在一同,咱们失掉了gpt2.py,它总共只要120行代码(假设删除注释和空格,则为60行)。
咱们可以经过以下方式测试咱们的实施:
它给出了输入:
它成功了!
咱们可以经常使用上方的Dockerfile测试咱们的成功与OpenAI官网GPT-2repo的结果能否分歧。
这应该会发生相反的结果:
下一步呢?
这个成功很酷,但它缺少很多花哨的物品:
将NumPy交流为JAX:
你如今可以经常使用代码与GPU,甚至TPU!只需确保正确装置了JAX即可。
反向流传
雷同,假设咱们用JAX交流NumPy:
再一次性,假设咱们用JAX交流NumPy:
推理优化
咱们的成成效率相当低。你可以启动的最快、最有效的优化(在GPU+批处置支持之外)将是成功KV缓存。
训练
训练GPT关于神经网络来说是相当规范的(梯度降低是损失函数)。
当然,在训练GPT时,你还须要经常使用规范的技巧包(例如,经常使用ADAM优化器、找到学习率、经过停学和/或权重衰减启动正则化、经常使用学习率调度器、经常使用正确的权重初始化、批处置等)。
训练一个好的GPT模型的真正秘诀是调整数据和模型的才干,这才是真正的应战所在。
关于缩放数据,你须要一个大、高品质和多样化的文本语料库。
-大象征着数十亿个token(TB级的数据)。
-高品质象征着您想要过滤掉重复的示例、未格局化的文本、不连接的文本、渣滓文本等。
评价
如何评价一个LLM,这是一个很难的疑问。
中止生成
以后的成功要求咱们提早指定要生成的token确实切数量。这并不是一个好方法,由于咱们生成的token最终会过长、过短或在句子中途终止。
为了处置这个疑问,咱们可以引入一个不凡的句尾(EOS)标志。
在预训练时期,咱们将EOStoken附加到输入的末尾(即tokens=["not","all","heroes","wear","capes",".","<|EOS|>"])。
在生成时期,只需咱们遇到EOStoken(或许假设咱们到达了某个序列长度),就会中止:
GPT-2没有预训练EOStoken,所以咱们不能在咱们的代码中经常使用这种方法。
无条件生成
经常使用咱们的模型生成文本须要咱们经常使用提醒符对其启动条件调整。
但是,咱们也可以让咱们的模型执行无条件生成,即模型在没有任何输入提醒的状况下生成文本。
这是经过在预训练时期将不凡的句子开局(BOS)标志附加到输入开局(即tokens=["<|BOS|>","not","all","heroes","wear","capes","."])来成功的。
而后,要无条件地生成文本,咱们输入一个只蕴含BOStoken的列表:
GPT-2预训练了一个BOStoken(称号为<|endoftext|>),因此经常使用咱们的成功无条件生成十分繁难,只需将以下行更改为:
由于咱们经常使用的是贪心采样,所以输入不是很好(重复),而且是确定性的(即,每次咱们运转代码时都是相反的输入)。为了失掉品质更高且不确定的生成,咱们须要间接从散布中抽样(现实状况下,在运行相似top-p的方法之后)。
无条件生成并不是特意有用,但它是展现GPT才干的一种幽默的方式。
微调
咱们在训练局部简明引见了微调。回忆一下,微调是指当咱们从新经常使用预训练的权重来训练模型执行一些下游义务时。咱们称这一环节为迁徙学习。
从通常上讲,咱们可以经常使用零样本或少样本提醒,来让模型成功咱们的义务,
但是,假设你可以访问token的数据集,微调GPT将发生更好的结果(在给定更少数据和更高品质的数据的状况下,结果可以裁减)。
有几个与微调相关的不同主题,我将它们细分如下:
分类微调
在分类微调中,咱们给模型一些文本,并要求它预测它属于哪一类。
例如,以IMDB数据集为例,它蕴含将电影评为好或差的电影评论:
为了微调咱们的模型,咱们将言语建模头交流为分类头,并将其运行于最后一个token输入:
咱们只经常使用最后一个token输入x[-1],由于咱们只须要为整个输入生成繁多的概率散布,而不是言语建模中的n_seq散布。
尤其,咱们驳回最后一个token,由于最后一个token是被准许关注整个序列的token,因此具无关于整个输入文本的消息。
像平常一样,咱们优化了w.r.t.交叉熵损失:
咱们还可以经过运行sigmoid而不是softmax来执行多标签分类,并失掉关于每个类别的二进制交叉熵损失。
生成式微调
有些义务不能被划一地归类。例如,总结这项义务。
咱们只需对输入和标签启动言语建模,就能对这类义务启动微调。例如,上方是一个总结训练样本:
咱们像在预训练中一样训练模型(优化w.r.t言语建模损失)。
在预测时期,咱们向模型提供直到---Summary---的一切内容,而后执行自回归言语建模以生成摘要。
分隔符---Article---和---Summary---的选用是恣意的。如何选用文本的格局由你自己选择,只需它在训练和推理之间坚持分歧。
留意,咱们还可以将分类义务制订为生成式义务(例如经常使用IMDB):
指令微调
如今,大少数进的大模型在经过预寻来你后,还会教训额外的指令微调。
在这一步中,模型对数千团体类标志的指令提醒+成功对启动了微调(生成)。指令微调也可以称为有监视的微调,由于数据是人为标志的。
那么,指令微调有什么好处呢?
只管预测维基百科文章中的下一个单词能让模型长于续写句子,但这并不能让它特意长于遵照指令、启动对话或总结文档(咱们宿愿GPT能做的一切事件)。
在人类标注的指令+成功对上对其启动微调,是一种教模型如何变得更有用,并使其更易于交互的方法。
这就是所谓的AI对齐,由于咱们正在对模型启动对齐,使其依照咱们的志愿行事。
参数高效微调
当咱们在上述章节中谈到微调时,假设咱们正在更新一切模型参数。
只管这能发生性能,但在计算(须要对整个模型启动反向流传)和存储(每个微调模型都须要存储一份全新的参数正本)方面老本高昂。
处置这个疑问最繁难的方法就是只更新头部,解冻(即不可训练)模型的其余局部。
只管这可以放慢训练速度,并大大缩小新参数的数量,但成果并不是特意好,由于咱们失去了深度学习的深度。
相反,咱们可以选用性地解冻特定层,这将有助于复原深度。这样做的结果是,成果会好很多,但咱们的参数效率会降低很多,也会失去一些训练速度的优化。
值得一提的是,咱们还可以应用参数高效的微调方法。
以Adapters一文为例。在这种方法中,咱们在transformer块中的FFN和MHA层之后参与一个额外的「适配器」层。
适配层只是一个繁难的两层全衔接神经网络,输入输入维度为n_embd,隐含维度小于n_embd:
暗藏维度的大小是一个超参数,咱们可以对其启动设置,从而在参数与性能之间启动掂量。
论文显示,关于BERT模型,经常使用这种方法可以将训练参数的数量缩小到2%,而与齐全微调相比,性能只遭到很小的影响(<1%)。
欢迎大家参与AiBase交流群,扫码进入,畅谈AI赚钱心得,共享最新行业灵活,发现潜在协作同伴,迎接未来的赚钱时机!。
(揭发)
AI正版系统源码介绍:小狐狸GPT-AI付费创作系统+开源可二开+私有常识库+聚合15家干流AI接口

检查节点Docker配置1. 打开Docker配置文件(示例是centos 7)vim/etc/sysconfig/docker2. 添加-H tcp://0.0.0.0:2375到OPTIONSOPTIONS=-g/cutome-path/docker-Htcp://0.0.0.0. CentOS6.6 需要另外添加-H unix:///var/run/=-g/mnt/docker-Htcp://0.0.0.0:2375-Hunix:///var/run/分别给A、B节点安装swarm$dockerpullswarm生成集群token(一次)$dockerrun--rmswarmcreatecdefdeca4b7e1de38e8其中cdefdeca4b7e1de38e8就是我们将要创建集群的token添加节点A、B到集群$dockerrun-dswarmjoin--addr=192.168.20.1:2375token://cdefdeca4b7e1de38e8$dockerrun-dswarmjoin--addr=192.168.20.2:2375token://cdefdeca4b7e1de38e8列出集群A、B节点$dockerrun--rmswarmlisttoken://cdefdeca4b7e1de38e8192.168.20.1.168.20.2:2375集群管理:在任何一台主机A、B或者C(C:192.168.20.3)上开启管理程序。 例如在C主机开启:$dockerrun-d-p8888:2375swarmmanagetoken://cdefdeca4b7e1de38e8现在你就可以在主机C上管理集群A、B:$docker-H192.168.20.3:8888info$docker-H192.168.20.3:8888ps$docker-H192.168.20.3:8888logs...在集群上运行容器$docker-H192.168.20.3:8888run-d--nameweb1nginx$docker-H192.168.20.3:8888run-d--nameweb2nginx$docker-H192.168.20.3:8888run-d--nameweb3nginx$docker-H192.168.20.3:8888run-d--nameweb4nginx$docker-H192.168.20.3:8888run-d--nameweb5nginx查看集群A、B内的容器$docker-H192.168.20.3:8888ps-a结果如下:
## 背景 ##我最初使用Docker的时候,每个人都在说它用起来有多简单方便,它内部的机制是有多么好,它为我们节省了多少时间。
但是当我一使用它就发现,几乎所有镜像都是臃肿而且不安全的(没有使用包签名,盲目相信上游的镜像库以curl | sh的方式安装),而且也没有一个镜像能实现Docker的初衷:隔离,单进程,容易分发,简洁。
Docker镜像本来不是为了取代复杂的虚拟机而设计的,后者有完整的日志、监控、警报和资源管理模块。
而Docker则倾向于利用内核的cgroups和namespaces特性进行封装组合,这就好像:在物理机器环境下,一旦内核完成了初始化,init进程就起来了。
这也是为什么当你在Dockerfile的CMD指令启动的进程PID是1,这是与Unix中的进程机制类似的。
现在请查看一下你的进程列表,使用top或者ps,你会看到init进程占用的也是这个PID,这是每个类Unix系统的核心进程,所有进程的父进程,一旦你理解这个概念:在类Unix系统上每个进程都是init进程的子进程,你会理解Docker容器里不应该有无关的修饰文件,它应该是刚好满足进程运行需要。
如何开始现在的应用多数是大型复杂的系统,通常都需要很多依赖库,例如有调度,编译和很多其他相关工具类应用,它们的架构通常封装性良好,通过一层层的抽象和接口把底层细节隐藏了,从某种程度上说,这也算是一种容器,但是从系统架构视角看,我们需要一种比以往虚拟环境更简单的方案了。
以Java为例从零开始,思考你要构建一个最通用的基础容器,想想你的应用本身,它运行需要什么?可能性有很多,如果你要运行Java应用,它需要Java运行时;如果运行Rails应用,它需要Ruby解释器,对Python应用也一样。
Go和其他一些编译型语言有些许不同,我以下会提到。
在Java例子中,下一步要想的是:JRE需要什么依赖才能运行?因为它是让应用能运行的最重要的组件,所以很自然的下一步就是要想清楚JRE运行依赖于什么。
而实际上JRE并没太多依赖,它本来就是作为操作系统的抽象层,使代码不依赖于宿主系统运行,因此安装好JRE就基本准备就绪了。
(实际上,对操作系统的独立性并不是理所当然的事,有非常多的系统特有API和专有的系统扩展,但是便于举例,我们把注意力放在简单的情况下)在Linux上,JVM主要是调用系统的C语言库,Oracle的官方JRE,使用的是libc,也就是glibc,这意味着你要运行任何Java程序,都需要先装好glibc。
另外你可能需要某种shell来管理环境,还有一个与外部通讯的接口,例如网络和资源的接口。
我们总结一下Java应用示例需要的最低配置是:JRE,在例子中我们使用Oracle JREglibc,JRE的依赖一个基础环境(包含网络、内存、文件系统等资源管理工具)## 走进Alpine Linux ##Alpine Linux最近得到很多关注,主要是因为它打包了一系列的经过验签的可信任的依赖,并且还保持体积在2MB!而在本文发布时,其他的一些镜像分发版如下:ubuntu:latest: 66MB (已经瘦身了非常多了,以前有些版本超过600MB)debian:latest: 55MB (同上,一开始是200MB以上的)arch:latest: 145MBbusybox:latest: 676KB (是的!KB,我稍后会讨论它)alpine:latest: 2MB (2MB,包含一个包管理工具的Linux系统)** Busybox是最小的竞争者?**从上边的对比中你可以看到,在体积上唯一能打败Alpine Linux的是Busybox,所以现在几乎所有嵌入式系统都是使用它,它被应用在路由器,交换机,ATM,或者你的吐司机上。
它作为一个最最基础的环境,但是又提供了足够容易维护的shell接口。
在网上有很多文章解释了为什么人们会选择Alpine Linux而不是Busybox,我在这总结一下:开放活跃的软件包仓库:Alpine Linux使用apk包管理工具,它集成在Docker镜像中,而Busybox你需要另外安装一个包管理器,例如opkg,更甚者,你需要寻找一个稳定的包仓库源(这几乎没有),Alpine的包仓库中提供了大量常用的依赖包,例如,如果你仍然需要在容器中编译NodeJS或Ruby之类的代码,你可以直接运行apk来添加nodejs和ruby,这在几秒内便可以完成。
体积确实重要,但是当你在功能性,灵活性,易用性和1.5MB之间衡量,体积就不那么重要了,Alpine上添加的包使这些方面都大大增强了。
广泛的支持:Docker公司已经聘请了Alpine Linux的作者来维护它,所有官方镜像,在以后都将基于Alpine Linux来构建。
没有比这个更有说服力的理由去让你在自己的容器中使用它了吧。
希云cSphere 很早就意识到镜像越来越庞大的问题,因此在去年推出 微镜像 ,也是引导大家如何更好地构建和理解镜像,镜像只是一种软件包格式而已。
** 构建一个Java环境基镜像 **正如我刚解释的,Alpine Linux是一个构建自有镜像时不错的选择,因此,我们在此将使用它来构建简洁高效的Docker镜像,我们开始吧!组合:Alpine + bash每个Dockerfile第一个指令都是指定它的父级容器,通常是用于继承,在我们的例子中是alpine:latest:shFROM alpine:latestMAINTAINER cSphere <>我们同时声明了谁为这个镜像负责,这个信息对上传到Docker Hub的镜像是必要的。
就这样,你就有了往下操作的基础,接下来安装我们选好的shell,把下边的命令加上:shRUN apk add --no-cache --update-cache bashCMD [/bin/bash]最终的Dockerfile是这样:```shFROM alpine:latestMAINTAINER cSphere < >RUN apk add --no-cache --update-cache bashCMD [/bin/bash]```好了,现在我们构建容器:sh$ docker build -t my-java-base-image build context to Docker daemon 2.048 kBStep 1 : FROM alpine:latest ---> 2314ad3eeb90Step 2 : MAINTAINER cSphere <> ---> Running in d77e ---> bfeaRemoving intermediate container d77e... 省略若干行Step 4 : CMD /bin/bash ---> Running in db797 ---> ecc443d68f27Removing intermediate container db797Successfully built ecc443d68f27并且运行它:sh$ docker run --rm -ti my-java-base-imagebash-4.3#
还是大品牌的好,比如佳能的。 售后比较有保障。 推荐HF M52这一款,配备Wi-Fi功能,并兼容DLNA网络设备,全高清画质,内置大容量存储器特别实用。
内容声明:
1、本站收录的内容来源于大数据收集,版权归原网站所有!
2、本站收录的内容若侵害到您的利益,请联系我们进行删除处理!
3、本站不接受违法信息,如您发现违法内容,请联系我们进行举报处理!
4、本文地址:https://www.gxyuehai.com/article/752098237c72529bfcf7.html,复制请保留版权链接!

这两个车型在血缘上宝来要更地道一些,宝来是公众的世界车型,而朗逸是上海公众针对中国市场研发的一款中国独有车型!空间上朗逸要稍稍好一点,然而行驶质感上宝来是要强于朗逸的!公众宝来和朗逸哪个好同排量下发起机变速箱和悬挂都是一样的,只是形状内饰性能的不同,宝来性价比稍好一点,后屁股照旧普通,做工比朗逸好那么一点点,...。
综合信息 2024-04-26 14:58:14

生肖是中国传统文化中的一种纪年方式,使用十二种动物作为代表,分别为鼠、牛、虎、兔、龙、蛇、马、羊、猴、鸡、狗、猪,每十二年为一个轮回,每个年份都对应一个生肖动物,如何计算你的生肖动物,计算生肖动物的方式很简单,将你的出生年份减去4,然后对12取余,余数代表你的生肖动物,0→鼠1→牛2→虎3→兔4→龙5→蛇6→马7→羊8→猴9→鸡10→...。
综合信息 2024-04-28 03:47:15

在英语写作中,however是一个常见的连接词,它的作用非常重要,在句子中,however的主要作用是引出一个对比、转折或修饰前文内容的观点或信息,它常常用于连接两个相对矛盾或对立的观点,起到了平衡句子结构和展示复杂思想的作用,However可以被放置在句子的开头、中间或结尾,具体位置取决于强调的重点和句子的流畅性,当它位于句子开头时...。
综合信息 2024-03-24 15:47:16

了解flow的含义及其重要性,了解Flos家具价格,在我们日常生活中,flow这个词可能很容易被忽视,但实际上它承载了丰富的内涵和重要性,让我们深入了解flow的含义及其重要性,以及探讨Flos家具的价格,flow的含义Flow这个词源自英文,意指流动、顺畅、连贯的状态,在心理学上,flow也被称为心流,指的是人们在专注于某项活动时,...。
综合信息 2024-03-04 08:04:39

120开头的身份证是哪里的,120开头的身份证是哪里的,身份证号码中的前6位数字代表户籍所在地的行政区划代码,通常被称为,身份证号码前6位地址码,其中,120开头的身份证号码主要指代天津市,天津市是我国的直辖市之一,位于华北地区,是重要的经济、金融中心,根据,中华人民共和国居民身份证法,,身份证号码前6位地址码的编制原则是根据地域...。
综合信息 2024-03-04 14:02:58

1升油等于多少斤,升等于多少斤,解密升和斤之间的关系,在日常生活中,升和斤是常见的计量单位,用于衡量液体和固体的重量,许多人可能会疑惑,1升等于多少斤呢,本文将对升和斤之间的关系进行解密,并详细分析这两个单位的定义和转换方法,升是国际制量衡系统,SI,中的容量单位,表示液体的体积,在中国,1升等于1000毫升,升的符号是L,来自于法语...。
综合信息 2024-02-12 23:10:09

印堂发黑是什么样子图片,印堂发黑是什么征兆,揭秘背后的含义,印堂发黑是指人的额头部位出现黑色素沉积,给人一种印堂发黑的视觉效果,印堂位于眉毛的正中央,被认为是人体的第六感官区域,也是决定命运和智慧的所在,据说,印堂发黑可能预示着一些特殊的征兆,具有一定的象征意义和神秘的含义,我们来看看印堂发黑的可能征兆,印堂发黑有以下几种可能的情况,...。
综合信息 2024-02-11 10:07:52
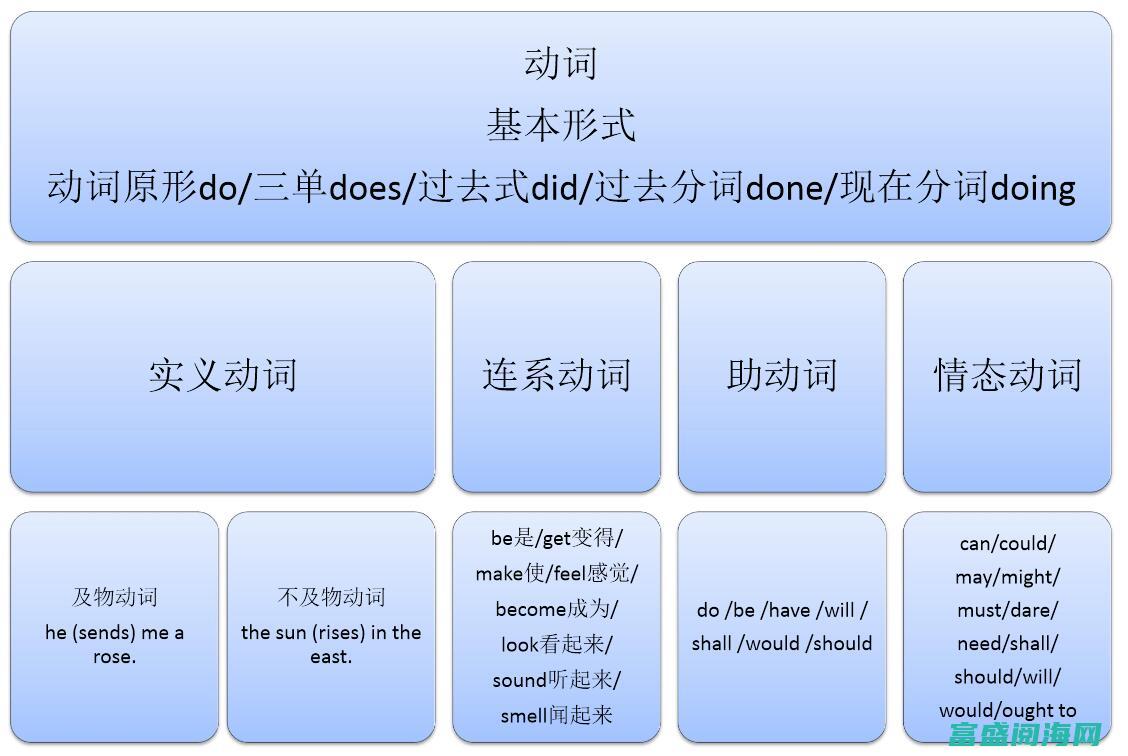
了解不及物动词是什么,了解不及物动词的含义及用法,了解不及物动词,intransitiveverbs,是中文语法中一个重要的概念,它与及物动词,transitiveverbs,相对应,但其特点在于不需要承受动作的对象,了解不及物动词的含义,不及物动词是指在句子中没有宾语的动词,它们只能有主语,而没有承受动作的对象,例如,像,笑,、,跑...。
综合信息 2024-02-22 06:07:21

招呼亲戚吃饭发短语怎么说,招呼亲戚吃饭1家17口被埋,史上最惊险的聚餐故事曝光,招呼亲戚吃饭是我们中国文化中的一种传统习俗,是表达亲情和团聚的重要方式,不管是在日常生活中还是在特殊场合,邀请亲戚一起吃饭都是一种常见的社交活动,有时候在招呼亲戚吃饭的过程中,也会发生一些令人意想不到的事情,在近期,有一则关于招呼亲戚吃饭的新闻引起了人们的...。
综合信息 2024-02-11 21:55:25

ul标记之间必须使用li标记的作用是,不使用ul标签,生成一个长标题,q51尺寸,在HTML中,ul,unorderedlist,标签用于创建一个无序列表,而li,listitem,标签则用于定义列表项,ul标记之间必须使用li标记的作用是为了在ul标签中创建多个列表项,每个列表项都由一个li标签来表示,使用ul和li标签的结构可以使...。
综合信息 2024-01-20 15:56:06

宫锁连城步青云的出现有什么意义,宫锁连城步青云,宫锁连城步青云,是一部以历史为背景的古装剧,通过讲述宫廷权力斗争和爱情故事展现了当时社会的复杂性和人性的复杂性,其中,步青云这个角色的出现具有重要的意义,步青云作为剧中的女主角,代表了女性在古代社会中的奋斗与坚韧,在清朝,女性的地位一直较低,受到男性的压迫和束缚,步青云并不甘于被动地接...。
综合信息 2024-01-11 02:10:55
